Quiz แก้ง่วง
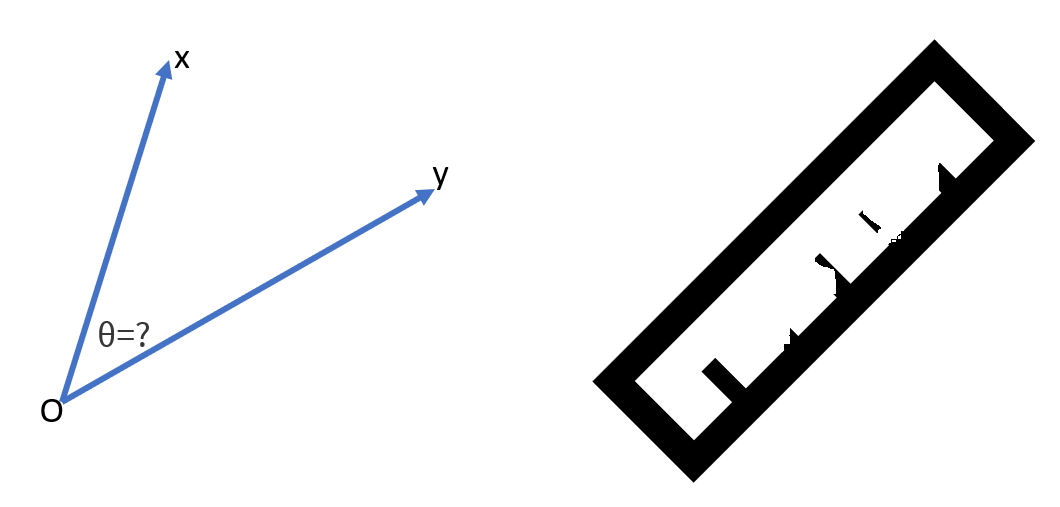
โจทย์
สมมติว่าเรามีเวคเตอร์ 2 อันคือ \(x\) และ \(yy\) และเราต้องการวัดมุมระหว่างเวคเตอร์ทั้งสองนี้ แต่โชคร้ายที่เราไม่มีไม้โปร เรามีแค่ไม้บรรทัดเก่า ๆ ที่วัดระยะอะไรไม่ค่อยได้แล้ว เราจะประมาณค่ามุม \(\theta\) ได้ยังไง?
Warm-up
Dot product ระหว่าง \(x\) และ \(y\) หรือ \(x^T y\) นั้นมีคุณสมบัติหนึ่งที่น่าสนใจคือ
\[x^T y = \|x\| \|y\| \cos \theta\]ซึ่งแสดงความสัมพันธ์ระหว่าง dot product ระหว่างเวคเตอร์ทั้งสอง และมุม \(\theta\) ระหว่างสองเวคเตอร์นี้
นั่นแปลว่าค่า sign (บวก หรือ ลบ) ของ dot product นั้นขึ้นกับค่า cos ของมุมนั่นเอง เพราะขนาดของเวคเตอร์มากกว่าหรือเท่ากับ 0 เสมอ
เรารู้ว่าค่า cos นั้นเป็นบวกในช่วง 0 บวก/ลบ 90 องศา หรือ \(\pi/2\)
นั่นแปลว่าเวคเตอร์ \(w\) ใด ๆ สามารถแบ่งปริภูมิออกเป็นสองส่วนนั่นคือส่วนที่ dot กับ \(w\) แล้วเป็นบวกหรือ 0 และส่วนที่ dot แล้วติดลบ โดยที่ขอบเขตระหว่างสองส่วนนี้คือตำแหน่งที่ค่า dot เป็น 0 พอดี นั่นคือ cos ของ \(\pi/2\) หรือมุมฉาก ซึ่งขอบเขตนี้ก็คือ hyperplane หรือ ระนาบเกิน นั่นเอง
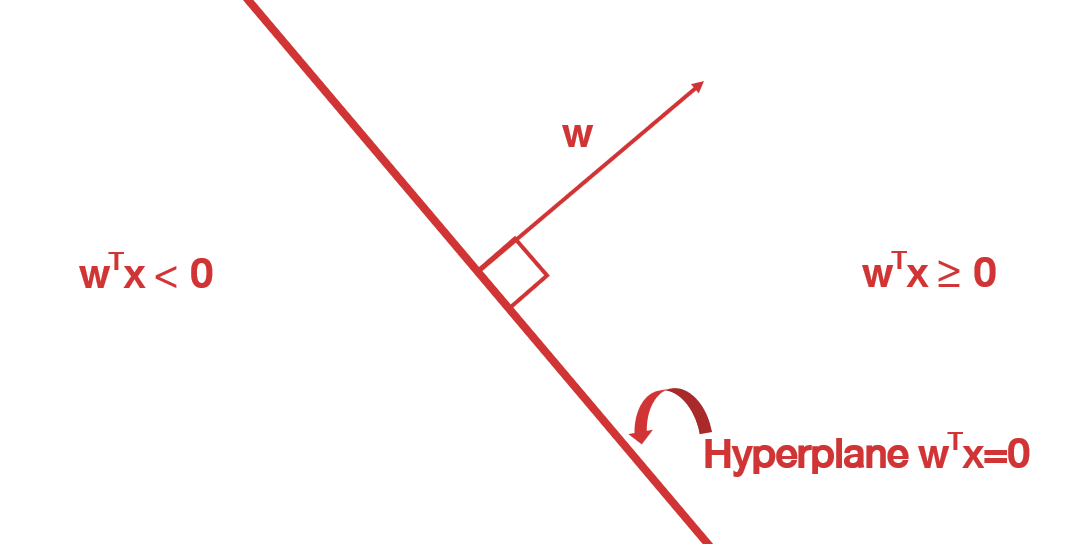
จากข้อสังเกตนี้ หากเราต้องการแบ่ง space ใด ๆ ออกเป็นสองส่วน เราก็สามารถทำได้โดยการเลือกเวคเตอร์ที่เหมาะสมมาใช้ นี่คือหลักการที่มาของ linear classifier นั่นเอง
Next: lemma quiz
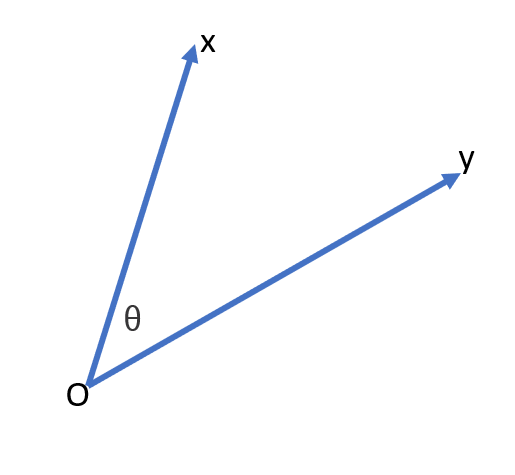
ก่อนจะไปดูเฉลย มาดูอีกคำถามนึงที่ใช้ความรู้ข้างบนในการตอบ
สมมติว่าเรามีเวคเตอร์ \(x\) และ \(y\) ใด ๆ โดยให้ \(\theta\) เป็นมุมระหว่างเวคเตอร์ทั้งสอง จงคำนวณ
\[P\left( w | (w^T x) (w^T y) < 0 \right)\]เพื่อตอบคำถามนี้ สังเกตว่า \((w^T x) (w^T y) < 0\) นั้นแปลว่า hyperplane ที่เกิดจากเวคเตอร์ \(w\) นั้น แบ่ง \(x\) และ \(y\) ไว้คนละฝั่ง
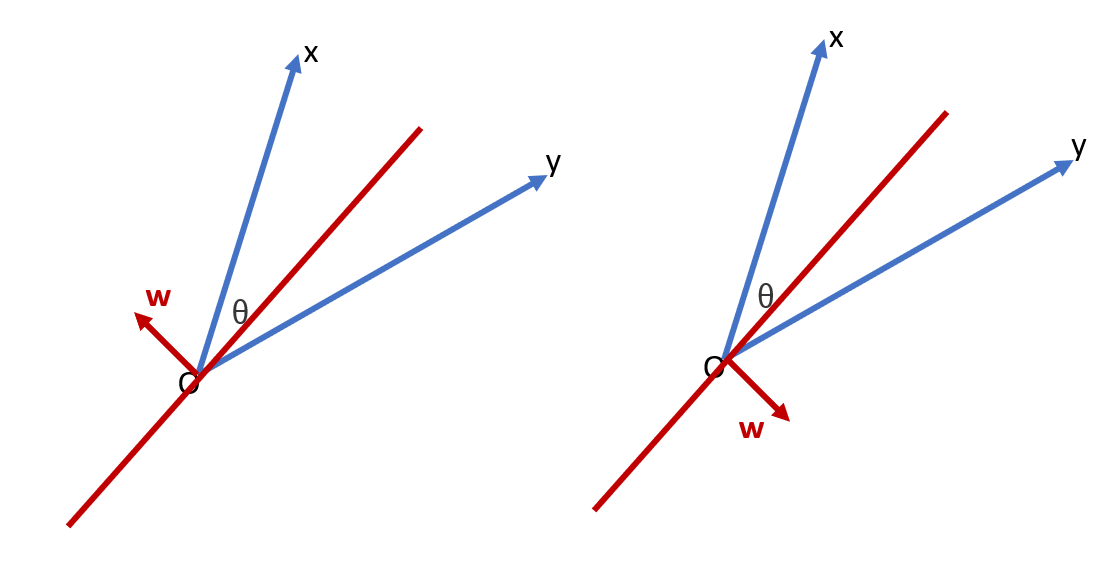
ความน่าจะเป็นที่จะสุ่มได้ \(w\) ที่แบ่ง \(x\) อยู่ในฝั่งบวก และ \(y\) อยู่ในฝั่งลบ (ภาพบนด้านซ้าย) ก็คือ \(\theta / (2 \pi)\) ซึ่งเท่ากับความน่าจะเป็นที่จะสุ่มได้ \(w\) ที่แบ่ง \(x\) อยู่ในฝั่งลบ และ \(y\) อยู่ในฝั่งบวก (ภาพบนด้านขวา) ดังนั้น
\[P\left( w | (w^T x) (w^T y) < 0 \right) = \frac{\theta}{\pi}\]แล้วไงต่อ?
ในโจทย์ข้างบนนี้เราเลือก \(w\) จากการ สุ่ม นั่นคือหากเรามีไม้บรรทัด ถึงแม้ว่าจะวัดระยะอะไรไม่ได้ก็ตาม ขอแค่ขีดเส้นตรงผ่านจุดกำเนิดได้ก็พอ แต่อย่าลืมกำหนดไว้ด้วยว่าสำหรับแต่ละเส้น จะให้ฝั่งไหนป็นบวก และฝั่งไหนเป็นลบ
สมมติว่าเราเตรียม \(w\) ไว้ 1,000 แบบ เมื่อเราได้ \(x\) และ \(y\) มา เราก็สามารถนับได้ง่าย ๆ ว่ามี \(w\) กี่ตัวที่แบ่ง \(x\) และ \(y\) ไว้คนละข้าง เมื่อนำจำนวนที่นับได้มาหาร 1,000 เราก็จะได้ \(P\left( w | (w^T x) (w^T y) < 0 \right)\) ซึ่งเมื่อรวมกับสมการที่ได้ก่อนนี้เราก็สามารถสลับข้างเพื่อให้ด้ค่าของ \(\theta\) นั่นเอง
Epilogue
เรายังสามารถประยุกต์ใช้แนวคิดข้างบนนี้กับการค้นหา เพื่อนบ้าน หรือกลุ่มของเวคเตอร์ที่อยู่ ใกล้ กับเวคเตอร์นำเข้า หรือ nearest neighbors search ได้อีกด้วย
โจทย์ nearest neighbors search เป็นโจทย์คลาสสิกในงาน Machine Learning หรือ Data Mining ซึ่งในงานพวกนี้เวคเตอร์ที่เราพิจารณามักมีหลายมิติมากๆๆๆ การค้นหาเพื่อนบ้านโดยอิงการคำนวณระยะทางปกติ (ระยะห่างแบบยูคลิด หรือ Euclidean distance) นั้นเป็น floating point operation กินเวลามาก และยิ่งกินเวลาเพิ่มหากจำนวนมิติของข้อมูลใหญ่ขึ้น
ในย่อหน้าก่อนนี้ที่เราสุ่ม \(w\) มาจำนวนหนึ่งนั้นจุดประสงค์คือเพื่อเป็น reference ว่าเวคเตอร์ \(v\) ใด ๆ นั้นจะตกอยู่ในฝั่งบวกหรือลบ ซึ่งผลลัพธ์นี้สามารถจัดก็บลงข้อมูลเพียง 1 บิต เท่านั้น นั่นคือหากเราสุ่ม \(w\) มา 1,000 ตัว เราก็สามารถเก็บรหัสบวก/ลบ ของ \(v\) ลงบน 1,000 บิต ได้
นั่นทำให้เราสามารถหามุมระหว่างเวคเตอร์ใด ๆ ได้จาก bit operation ซึ่งทำได้เร็วกว่า floating point operation มาก
นี่คือหนื่งใน idea พื้นฐานสำหรับ approximate nearest neighbor search นั่นเอง
สุขสันต์วันวาเลนไทน์นะครับ :D